
数据分析能力养成指南11:SQL,从熟练到掌握

我们在上一篇《数据分析能力养成指南10:SQL,从入门到熟练》文章已经掌握了除Join外的常用语法和函数,今天会通过一系列的练习彻底掌握SQL。
我们知道,数据库由多张表组成,表与表之间可以实现关联。
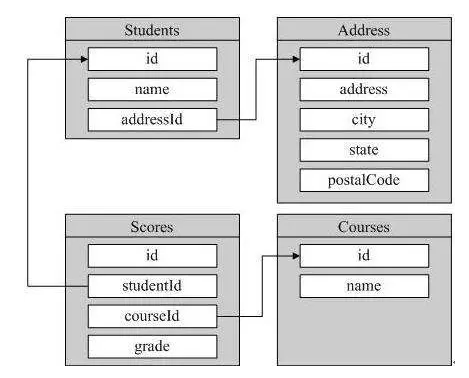
上图就是一个简单的关联模型:
Students.addressId = Address.id
Students.id = Scores.studentId
Scores.courseId = Courses.id
那么,如何在SQL查询语句中将两个表联接起来?我们将运用最重要的语法Join。
select * fromStudents
joinAddress onStudents.addressId = Address.id
上面语句,join将Students和Address两表关联,关联需要一个或多个字段作为联接桥梁。例子中的桥梁就是addressid,我们使用on语句,将Students表的addressId字段和Address的id字段匹配。
这里需要注意的是,因为字段可能重名,所以一旦使用了Join,字段前应该加上表名,如Students.addressId和Address.id ,这种用法是为了字段的唯一性,否则遇到重名,系统不知道使用哪个字段,就会报错。
select * fromStudents ass
joinAddress asa ons.addressId = a.id
上图是更优雅的写法,将表命名为一个缩略的别名,避免了语句过于冗余。不要使用拼音做别名,不是好习惯。
Join语法有很多不同的变形,Left Join,Outer Join等,新人很容易混淆。这个我们可以用数学中的交集和并集掌握。
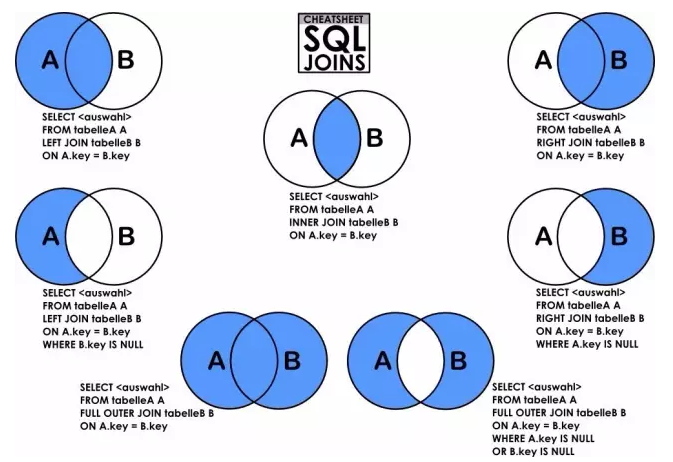
上图很清晰地解释了各Join语法。
Inner Join最常见,叫做内联接,可以缩写成Join,找的是两张表共同拥有的字段。
Left Join叫做左联接,以左表(join符号前的那张表)为主,返回所有的行。如果右表有共同字段,则一并返回,如果没有,则为空。
我们以W3School上的数据为例:
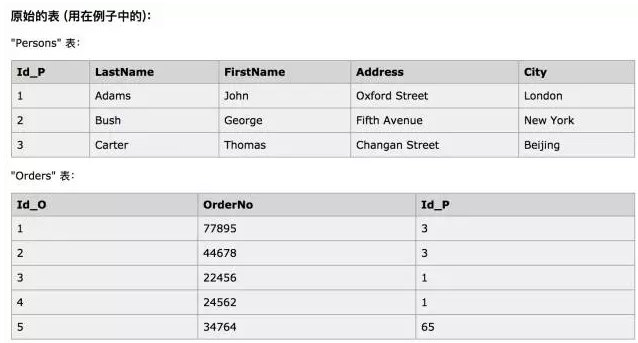
select Persons.LastName, Persons.FirstName, Orders.OrderNo
fromPersons
left joinOrders onPersons.Id_P=Orders.Id_P
order byPersons.LastName
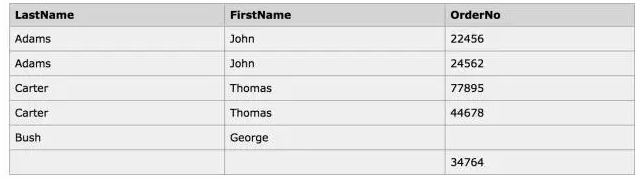
于是输出结果为:

结果集中,Bush那一行的OrderNo为空,就是因为Id_P无法匹配上,返回了Null。如果改成Inner join,则不会返回整个Bush所在行。这是Inner Join和Left Join的区别,也是面试中经常会问到的题目。
Right Join和Left Join没有区别,A Left Join B 等价于 B Right Join A。
Full Join叫做全联接,也叫做Full Outer Join,意思是不管有的没的,只要存在,就返回。
还是以之前的例子演示,下面是Full Join:
最后两行就是所谓的「不管有的没的,只要存在字符串,就返回」的结果,它们Id_P并没有匹配上,但还是给出了返回,只是为空字段不同。
这三者的关系,我们可以理解为:A Full Join B = A Left Join B + A Right Join B – A Inner Join B,这就是数学上的集合运算,虽然SQL的表并不能加减法。如果还一知半解,看最上面的Join示例图,用面积的角度看也明白了。
通过上面的例子,我们已经掌握了Join的主流语法,其他无非是变种。比如加约束条件 where XX is null,这里的XX可以是结果为空的字段。拿上文Left Join的例子演示:
select Persons.LastName, Persons.FirstName, Orders.OrderNo
fromPersons
left joinOrders
onPersons.Id_P=Orders.Id_P
whereOrders.Id_P is Null
最终返回的结果就是Bush这一行。
当我们有多个字段要匹配时,on后面可以通过 and 进行多项关联。
select * fromA
joinB onA.name = B.nameandA.phone = B.phone
上图就是一个简单的适用场景,将用户姓名和手机号进行多项关联。它也可以加入其他的条件判断。
select * fromA
joinB onA.name = B.nameandA.phone = B.phone andB.sex = ‘男
我们再加一个and,将B表的用户性别限定为男。这种用法等价于where B.sex = ‘男’。当数据量大到一定程度,通过这种约束条件,能优化查询性能。
到这里,SQL的常用语法已经讲解的差不多了,我们进行实战吧。leetcode.com网站是知名的算法竞赛题,去上面刷SQL吧。
注册完后进入leetcode.com/problemset/database页面。那里有几道MySQL题目。因为时间关系,我只讲解Join相关,大家有兴趣可以刷其他题,都不难的。SQLZoo也能刷,就是页面丑了点,所以我十分感动地拒绝了它。
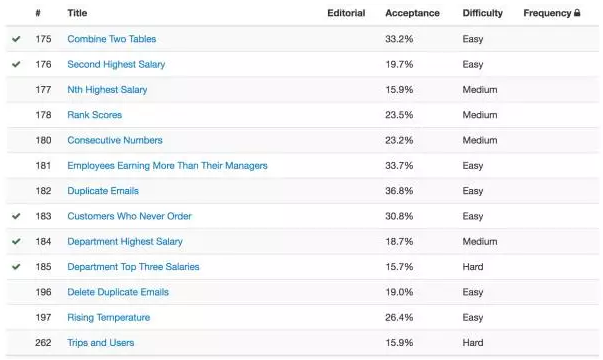
我们从Easy开始,选择题目Combine Two Tables。

红色字符是表名,第一列是字段名,第二列是数据类型。题目希望我们通过两张表输出:FirstName, LastName, City, State四个字段。
单纯的Inner Join就能完成了。记住噢,答案需要完全一致,也就是说最终的结果必须是四个字段,不能多不能少,顺序也不能乱,大小写要严格。这一题大家自己做吧。通过后会有个绿色的Accepted提示。
接下来选择Medium难度的Department Highest Salary。
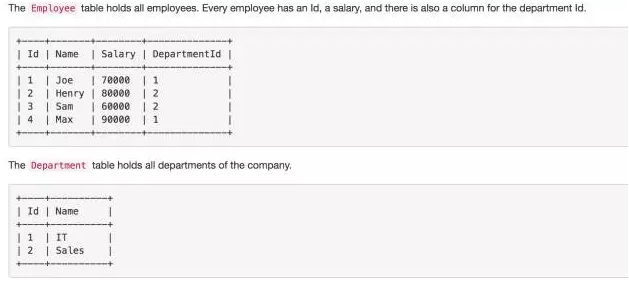
这里有两张表,员工表和部门表,我们希望找出各个部门的最高薪水。
部门信息单独为一张表,首先我们需要Join关联起来,将部门分组求出最大值:
select d.Id, #这是部门ID
d.NameasName, #这是部门名字
max(e.Salary) asSalary #这是最高薪水
fromDepartment d
joinEmployee e
one.DepartmentId = d.Id
group byd.Id
上述的查询语句找出了最高薪水的部门,我们是否能直接使用其作为答案?不能。这里有一个逻辑的小陷阱,当最高薪水非单个时,使用max会只保留第一个,而不是列举所有,所以我们需要更复杂的查询。
因为已经有了各部门最高薪水的数据,可以将它作为一张新表,用最高薪水关联雇员表,获得我们最终的答案。
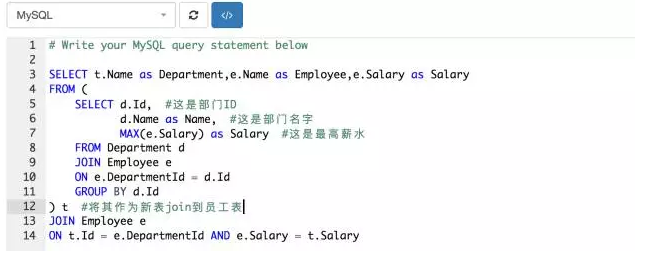
上面就是最终解法(#是解释给你们看的,中文会报错的),当然解法应该不是唯一的,大家有兴趣可以继续研究。
最终,我们选Hard模式的Department Top Three Salaries。
范例数据没有一丁点变化,它需要我们求出各部门薪水前三的数据。如果最高薪水只有两个,则输出两个。
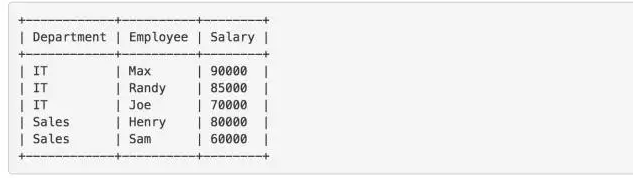
上图是给的范例结果。
排名前三的数据,我们可以使用order by 降序排列出来,然后通过limit 限定为3,但是新的问题是:既要各部门前三,也存在排名并列的情况。此时order by就无能为力了。
如果是SQL Server或者Oracle,我们可以使用row_number分组排序函数,但是MySQL没有,其中的一种思路是利用set语法设置变量,间接应用row_number。我们还能使用另外一种思路。
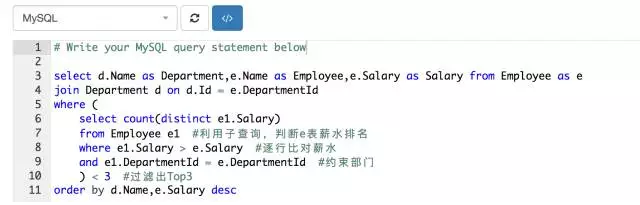
select * from Employee ase
where (
select count(distincte1.Salary)
fromEmployee e1
wheree1.Salary > e.Salary
ande1.DepartmentId = e.DepartmentId
) <3
上述的例子巧妙地借用了子查询。在where语句中,我们用子表e1与父表(外表)e进行比对。SQL是允许子查询的表和父查询的表进行运算的。
e1.DepartmentId = e.DepartmentId作为条件约束,避免跨部门。e1.Salary > e.Salary则是逻辑判断,通过count函数,逐行计算出e表中有多少薪水比e1的薪水低。
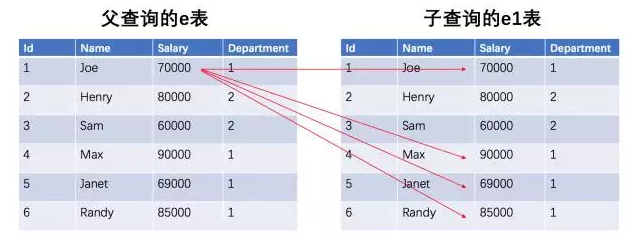
因为e1表和e表实际上是等价的。所以返回的count(distinct e1.Salary) 代表e1表有中多少薪水比e表的高,上图的例子,答案是2(90000和85000比它高)。如果是0,则代表e表中该行薪水最高(没有比它高的),1代表第二高,2代表第三高。于是便过滤出Top 3的薪水。最后通过join计算出结果。
在实际查询过程中,不建议大家使用这种运算方式,因为运算效率不会快。其实换我,我更可能group by后导出结果用Excel处理。
到这里,大家对Join已经有一个大概的了解了吧。真实的数据查询场景中,Join会用到很多,业务复杂用五六个Join也是常态,如果算上各类逻辑处理,SQL代码行数可以破百。这时候,考验的就是熟练度了。
SQL只要多加训练,并不是一门很难掌握的语言。除了技巧,还要看你对业务表的熟悉程度,一般公司发展大了,百来张表很正常,各类业务逻辑各种Join,各字段的含义,这是同样要花费时间的苦功夫。
希望大家对SQL已经有一个初步的掌握了。SQL学好了,以后应用大数据的Hive和SparkSQL也是轻而易举的。
接下来,我们将要进入第五周的大魔王课程,统计学,从入门到放弃,哈哈哈。
相关阅读
数据分析能力养成指南:Excel技巧之甘特图绘制(项目管理)
作者:秦路,微信公众号ID:tracykanc。
本文由 @秦路 原创发布。未经许可,禁止转载。
 等我一分钟 我去找个夸你的句子
等我一分钟 我去找个夸你的句子
 这世上美好的东西不多,牛起来要人命的你就是其一!
这世上美好的东西不多,牛起来要人命的你就是其一!
 不要厉害的这么随意,不然我会觉得我又行了
不要厉害的这么随意,不然我会觉得我又行了
 这就很离谱了,老天爷追着喂饭的主儿~
这就很离谱了,老天爷追着喂饭的主儿~
 我要是有这才华,我走路都得横着走!
我要是有这才华,我走路都得横着走!
 对你的作品崇拜!
对你的作品崇拜!
 反手就是一个推荐,能量满满!
反手就是一个推荐,能量满满!
 感谢分享
感谢分享































