
数据分析能力养成指南15:读了本文,你就懂了概率分布

本文是《如何七周成为数据分析师》的第十五篇教程,如果想要了解写作初衷,可以先行阅读七周指南。温馨提示:如果您已经熟悉概率分布,大可不必再看这篇文章,或只挑选部分。
我们已经了解概率的基础,概率中通常将试验的结果称为随机变量。随机变量将每一个可能出现的试验结果赋予了一个数值,包含离散型随机变量和连续型随机变量。
掷硬币就是一个典型的离散型随机变量,离散随机变量可以取无限个但可数的数值。而连续变量相反,它在某一个区间内能取任意的数值。时间就是一个典型的连续变量,1.25分钟、1.251分钟,1.2512分钟,它能无限分割。
既然随机变量可以取不同的值,统计学家就用概率分布描述随机变量取不同值的概率。相对应的,有离散型概率分布和连续型概率分布。
对于离散型随机变量x,定义一个概率函数叫f(x),它给出了随机变量取每一个值的概率。
拿出一个骰子,掷到6的概率是f(6) = 1/6,掷到1和6的概率则是f(1)+f(6) = 1/3。
数学期望和方差
现在有一个运营活动,两套抽奖概率方案,如下:

作为运营人员,应该怎么衡量两种抽奖方法的好坏呢?
数学期望是对随机变量中心位置的一种度量。是试验中每次可能结果的乘以其结果的总和。简单说,它是概率中的平均值,可以用期望对比两套方案。
![]()
假设一等奖成本1000元,二等奖成本500元,三等奖成本100元,欢迎下次再来当然没钱,而用户参加一次抽奖需要5元。我们将概率问题转换成运营方的收益和成本计算期望(下面的盈亏是公司角度的)。
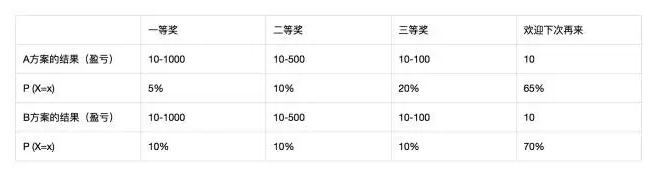
于是E(x) = (-990*5%)+(-490*10%)+(-90*20%)+(10*65%) = -110。也就是说,A方案能够期望每次抽奖运营方亏损110元。计算一下B方案,则是亏损150元。如果从用户的角度看,每一次抽奖的期望则反过来,即一等奖能受益990元,二等奖能受益490元…A方案玩一次平均收益110元。
想必大家已经知道了如何设计活动的盈亏机制,感兴趣可以自行调节中奖概率和成本。
期望值衡量概率的平均值,可是抽奖本来就是很激动人心的事情,哪怕明知道会赔钱,人们还乐此不疲,为什么?因为风险,因为以小搏大。
方差就是这种风险的度量,即随机变量的变异性。它和描述统计学的方差是一个含义。
![]()
方差越大,随机变量的结果越不稳定,计算A方案的方差如下:
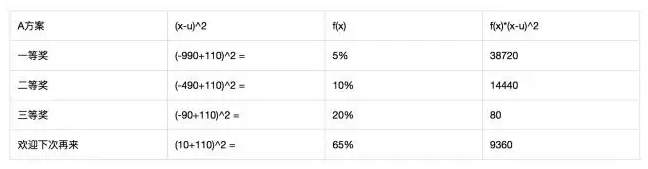
方差最后为62600,说明期望的波动很大。标准差为sqrt(62600) = 250.19,代表每一次的抽奖,与期望收益-110的距离是250.19元。
到这里,概率和期望方差的基本玩法已经讲完了。
二项概率分布
二项分布是一种离散型的概率分布。故明思义,二项代表它有两种可能的结果,把一种称为成功,另外一种称为失败。
除了结果的规定,它还需要满足其他性质:每次试验成功的概率均是相同的,记录为p;失败的概率也相同,为1-p。每次试验必须相互独立,该试验也叫做伯努利试验,重复n次即二项概率。
掷硬币就是一个典型的二项分布。当我们要计算抛硬币n次,恰巧有x次正面朝上的概率,可以使用二项分布的公式:
![]()
假设抛硬币5次,恰巧有3次正面朝上,则其概率为31.25%。可以使用Excel中的BINOM.DIST函数计算。
不妨把题目变化一下,变成计算硬币至少有三次正面朝上的概率是多少?有一种简单的方法是累加,将恰巧有3次,恰巧有4次,恰巧有5次的概率相加,结果便是至少3次,为50%。
回到运营活动的例子,上面一个运营活动公司亏惨了,现在运营需要重新做一个抽奖活动,每位用户拥有10次抽奖机会,中奖概率是5%。老板准备先考虑成本问题,想知道至少有3次以上中奖机会的概率是多少?
按照上题的思路,可以拿恰巧3次,恰巧4次直到恰巧10次累加求和,但是这样太麻烦了。此时可以换一个思路,先计算最多2次的概率是多少。那么便是f(0)+f(1)+f(2),结果是92.98%,利用概率公式1-92.98%,就是至少3次的概率了,为7.02%。看来老板还是能松口气的。
二项概率的数学期望为E(x) = np,方差Var(x) = np(1-p)。抽奖10次,那么抽奖的期望值就是1,方差为0.9。
运营学会二项分布,在涉及概率的各种活动中,将变得游刃有余。它的原理甚至能用到AB测试。大学考试中二项概率需要查专门的概率表计算,不过现在各类工具层出不穷,Python、R、Excel都能直接计算。
泊松概率分布
泊松概率是另外一个常用的离散型随机变量,它主要用于估计某事件在特定时间或空间中发生的次数。比如一天内中奖的个数,一个月内某机器损坏的次数等。
泊松概率的成立条件是在任意两个长度相等的区间中,时间发生的概率是相同的,并且事件是否发生都是相互独立的。
泊松概率既然表示事件在一个区间发生的次数,这里的次数就不会有上限,x取值可以无限大,只是可能性无限接近0,f(x)的最终值很小。
x代表发生x次,u代表发生次数的数学期望,概率函数为:
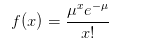
现在又举办了一个新的运营活动,这次的中奖概率未知,只知24小时内中奖的平均个数为5个,老板异想天开地想知道24小时内恰巧中奖次数为7的概率是多少?
此时x=7,u=5(区间内发生的平均次数就是期望),代入公式求出概率为10.44%。Excel中的函数为POISSON.DIST。
接下来继续加大问题难度,求中奖次数至少7次的概率。此时f(0)+f(1)+f(2)+f(3)+f(4)+f(5)+f(6)=86.66%,那么至少七次的概率为13.33%。
如果问题变成12小时内呢?老板希望知道12小时内中奖次数为3次的概率是多少?
24小时内中奖概率的期望数是5,那么12小时内的中奖概率期望数是2.5,于是令u=2.5,求出12小时内中奖次数为3的概率是79.99%。
泊松概率还有一个重要性质,它的数学期望和方差相等,所以上题的方差为2.5,标准差为根号2.5,即1.58。
正态分布
上述分布都是离散概率分布,当随机变量是连续型时,情况就完全不一样了。因为离散概率的本质是求x取某个特定值的概率,而连续随机变量不行,它的取值是可以无限分割的,它取某个值时概率近似于0。连续变量是随机变量在某个区间内取值的概率,此时的概率函数叫做概率密度函数。
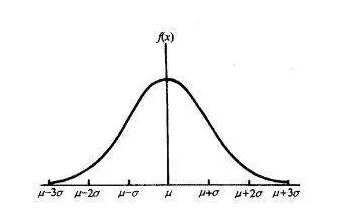
正态概率分布是连续型随机变量中最重要的分布。世界上绝大部分的分布都属于正态分布,人的身高体重、考试成绩、降雨量等都近似服从。
正态分布如同一条钟形曲线。中间高,两边低,左右对称。想象身高体重、考试成绩,是否都呈现这一类分布态势:大部分数据集中在某处,小部分往两端倾斜。
正态概率密度函数为:
![]()
是不是看得头晕了?u代表均值,σ代表标准差,两者不同的取值将会造成不同形状的正态分布。均值表示正态分布的左右偏移,标准差决定曲线的宽度和平坦,标准差越大曲线越平坦。
以前介绍过一个正态分布的经验法则:
正态随机变量有69.3%的值在均值加减一个标准差的范围内,95.4%的值在两个标准差内,99.7%的值在三个标准差内。这条经验法则可以帮助我们快速计算数据的大体分布。
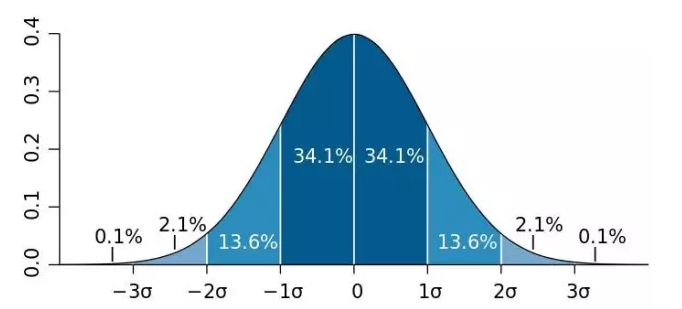
均值u=0,标准差σ=1的正态分布叫做标准正态分布。它的随机变量用z表示,它是推断统计的基础。将均值和标准差代入正态概率密度函数,得到一个简化的公式:
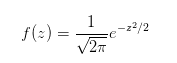
现在可以用简化的公式计算概率密度了。首先学习一个新的函数叫累计分布函数,它是概率密度函数的积分。用P(X<=x)表示随机变量小于或者等于某个数值的概率,F(x) = P(X<=x)。
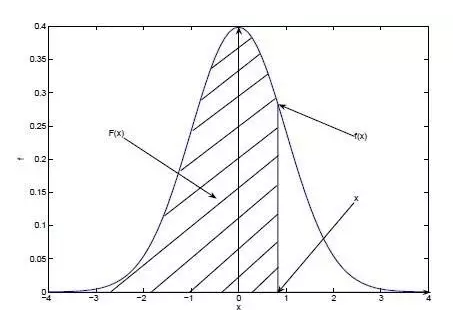
曲线就是概率密度函数,当x取某个值时,曲线上f(x)点的数值即表示随机变量在对应的x点值的取值概率,曲线与X轴相交的阴影面积就是累计分布函数。我们不妨把概率密度函数按其名字简单理解成「密度」,毕竟连续变量只有在区间中才有计算的意义,于是密度函数充当了辅助计算的角色。分析中我们更多实用累计分布函数。
标准正态分布中,给定一个值z,可以计算随机变量z小于等于某一个值的概率;z在两个值之间的概率;以及z大于等于一个值的概率。这三种计算都用到累计分布函数,分别记作P(z<=x),P(x1<=z<=x2),P(z>=x)。
首先计算z小于等于1的概率,即P(z<=1)。由excel 的函数NORM.DIST(1,0,1,TRUE)求得值为0.8413。于是P(z<=1)=0.8413。同理,P(z>1) = 1-P(z<=1) = 0.1586。
若要计算z在区间-1~1.25的概率,即P(-1<=z<=1.25)。可以将其拆解为公式:P(-1<=z<=1.25) = P(z<=1.25) – P(z<=-1) = 0.735。
如果大家在公式转换中有困惑,不妨结合上面的阴影图看。靠左的阴影即z小于等于0.8时(目测)的概率,如果我们要算0~0.8之间的概率呢?就是把z<=0的那一半给挖掉,非常粗暴的算法。
到了这里大家可能发觉,在正态分布的计算中,不论求哪一类区间,我们都是先转换成z小于等于某个值先计算。这是一个潜移默化的规则,因为早期正态概率的计算都要用到标准正态概率表,它以z小于等于作查询标准。现在虽然计算资源已经大大丰富,但是这个习惯还是保留了下来。
之所以强调标准正态分布,是因为所有的正态分布概率都可以利用标准正态分布计算。当我们具有一个任意均值的u和标准差σ,都能将其转换成标准状态分布。
![]()
现在有一个u=10和σ=2的正态随机变量,求x在10与14之间的概率是多少?
当x=10时,z=(10-10)/2=2。当x=14时,z=(14-10)/2=2。于是x在10和14之间的概率等价于标准正态分布中0和2之间的概率。计算P(0<=z<=2) =P(z<=2) – P(z<=0) =0.4772。
现在是最后一个运营活动了,不再是抽奖,而是最终赠送奖品的环节。已知奖品的保质期满足正态分布,均值90天,标准差5天。为了考虑用户体验,想知道奖品70天以内就坏的概率是多少?
当x=70时,有z=(70-90)/5 = -4。p(z<=-4)=0.003%。概率非常小,可以忽略不计,所以产品质量杠杠的。经历了那么多活动,老板终于可以松一口气了。
在概率分布中还有一个概念叫正态近似。当试验次数很大时,二项分布可以近似于正态分布,泊松分布也有相似的情况,大家有兴趣可以去了解,这是一种简便方法,不过工作中现在都是计算机了,这点反而不重要了。
了解完各类分布后,我们将进入最后的环节,假设检验,它是基于概率的理论,数据分析中的AB测试,就是其最常见的应用。
相关阅读
数据分析能力养成指南:Excel技巧之甘特图绘制(项目管理)
作者:秦路,微信公众号ID:tracykanc。
本文由 @秦路 原创发布。未经许可,禁止转载。
 等我一分钟 我去找个夸你的句子
等我一分钟 我去找个夸你的句子
 这世上美好的东西不多,牛起来要人命的你就是其一!
这世上美好的东西不多,牛起来要人命的你就是其一!
 不要厉害的这么随意,不然我会觉得我又行了
不要厉害的这么随意,不然我会觉得我又行了
 这就很离谱了,老天爷追着喂饭的主儿~
这就很离谱了,老天爷追着喂饭的主儿~
 我要是有这才华,我走路都得横着走!
我要是有这才华,我走路都得横着走!
 对你的作品崇拜!
对你的作品崇拜!
 反手就是一个推荐,能量满满!
反手就是一个推荐,能量满满!
 感谢分享
感谢分享
