
运营数据能力进阶:用户画像数据分析
如何通过数据清晰现有用户的画像,找到各个行业用户的核心关注点,来进行精细化的运营以提升用户的复购?如何将数据清晰梳理,整理出可以实际指导业务的指标呢?

业务数据复杂且多,如何通过海量数据定义出核心关注的指标,用以指导用户增长和转化?
如何通过数据知道用户体验产品的核心路径?如何设计产品的新手引导来提升用户的体验?引导更多用户体验到产品核心,成为“高转化可能”的用户?
用户运营时候,如何通过数据清晰现有用户的画像,找到各个行业用户的核心关注点,来进行精细化的运营以提升用户的复购?
这些可能是很多运营在面对海量数据的时候都想知道的。我们都知道数据有强大的能力,清洗后的数据更加能够指出一条清晰的前进道路。俗话说,一个不会看数据的运营不是一个好产品经理,作为一个主要通过看数据和用户访谈定性定量分析,然后产出相应策略指导增长的用户增长产品运营,今天要讲几个硬核的能力,帮助通过数据提升运营能力,制定运营策略
运营在数据分析的路上,有几道关,埋点,拿数据,分析,产出可行运营策略,每一关都困难重重
以下可能是运营去提取数据的真实场景:
运营:“我想看一下最近新上的功能用户使
用的如何,能不能给捞一下数据?”
开发:“看什么数据?”
运营:“就想看一下都有谁看了功能,又有谁买了,买的用户有什么特征,还有哪些使我们的目标用户可以再去推广一波”
开发:“到底需要什么字段?”
运营:“啥字段啊?能不能把这个客户使用过什么功能,使用的情况怎么样,属于深度用户还是流失用户,什么行业都导出来?”
开发:“使用了什么功能没问题,使用情况给出定义,是使用次数还是使用赚到的钱?还是使用时长?”
运营:“都可以啊”
开发:“你能不能想清楚,你到底要用来干嘛?什么叫都可以,我是运营你是运营”
这是很普遍的情况,也是可以理解的情况,因为运营的角度,是业务的角度,但开发的角度,是数据的角度,这个字段里没有你说的是不是活跃用户。这时候肯定就会想,好像要一套数据,能够清晰告诉我,这个用户是什么行业,使用了什么功能,是什么商业模式,处在什么状态啊!!
这就引出了一个问题,如何将数据清晰梳理,整理出这些可以实际指导业务的指标呢?
如何通过数据定义用户画像?
- 清晰定义想要的指标类型,例如是用户生命周期指标,产品使用行为指标,用户购买行为指标,用户能力行为指标,用户自然人属性指标……
- 和数据尽可能清晰的沟通,拿到尽可能详细的数据,注意,这里的数据最好在提取数据的时候就不要多维数据!不要多维数据!
- 处理数据并尽可能不要忽略可能对关键行为产生影响的指标,通过模型或者excel等其他高级(假装)的手段,通过宏观数据(整个行业用户数据或地区用户数据)和围观数据(详细到每个用户一条记录的数据)进行分析
- 根据分析结果,得出一套可以套用的指标体系,将指标自动打在各个用户身上
- 用户画像初步完成,之后可以再优化
指标定义——场景化定义便于明确需要提取的指标
在和数据或者开发沟通提取数据之前,首先需要思考希望得出一个什么样的画像结果,这里可以大胆使用假设,例如
“我希望看到用户A,是一个来自百度搜索的北京K12机构用户,他已经联系3年续费我们的产品了,但他们运营能力比较弱,使用的功能一直都是那么几个,没有用到我们推出的新功能,主要使用的就是直播功能和考试功能。他们机构的用户一直稳定在10万左右,其中还有3个运营在维护,在学生放假和考试时间使用尤其频繁。”
这样就很明确,一般我会分出两类型数据,然后再根据两个类型数据细化相关指标。
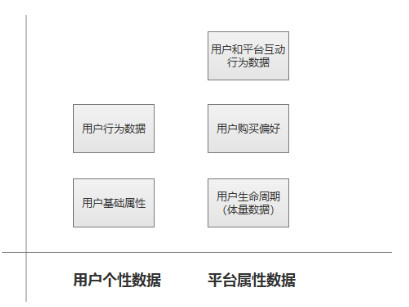
这里每一类数据都可以再细分出细化的数据指标,比如说用户基础数据可以如此细化,其他指标类型也可以如此,根据产品属性和需要了解的内容选取指标。
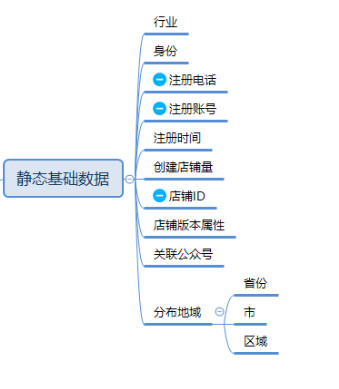
数据提取——多维数据的降维处理
清晰了指标定义,会发现,有一些指标,可能会涉及多维,没有办法进行比较和分析。
例如,用户使用成功创建了某种类型的商品,每个商品的售卖量和销量都不相同,在考虑该商品功能的使用时候如何进行综合处理?这里需要降维处理一下数据,可以加权平均,或者取众数,中位数进行代表,从而降低对比评价出现多维对比的情况。
数据分析——发现到底什么才是“最重要的指标”
一条用户记录,关联的数据字段是非常多的,一个用户,付费和不付费的核心差别点是什么?到底什么是让用户付费的关键?用户到底关注什么?
这可能需要借助分析来看清楚,这里的因变量(用户的付费)和哪些自变量是相关联的。在这里推荐一个算法,CHAID决策树,这类决策树专门用来找出这里面核心影响最终结果的变量是什么,也就是说,这么多功能,用户这么多行为,这么多属性,到底哪种属性类型的用户,哪种行为类型的用户,更容易转化!
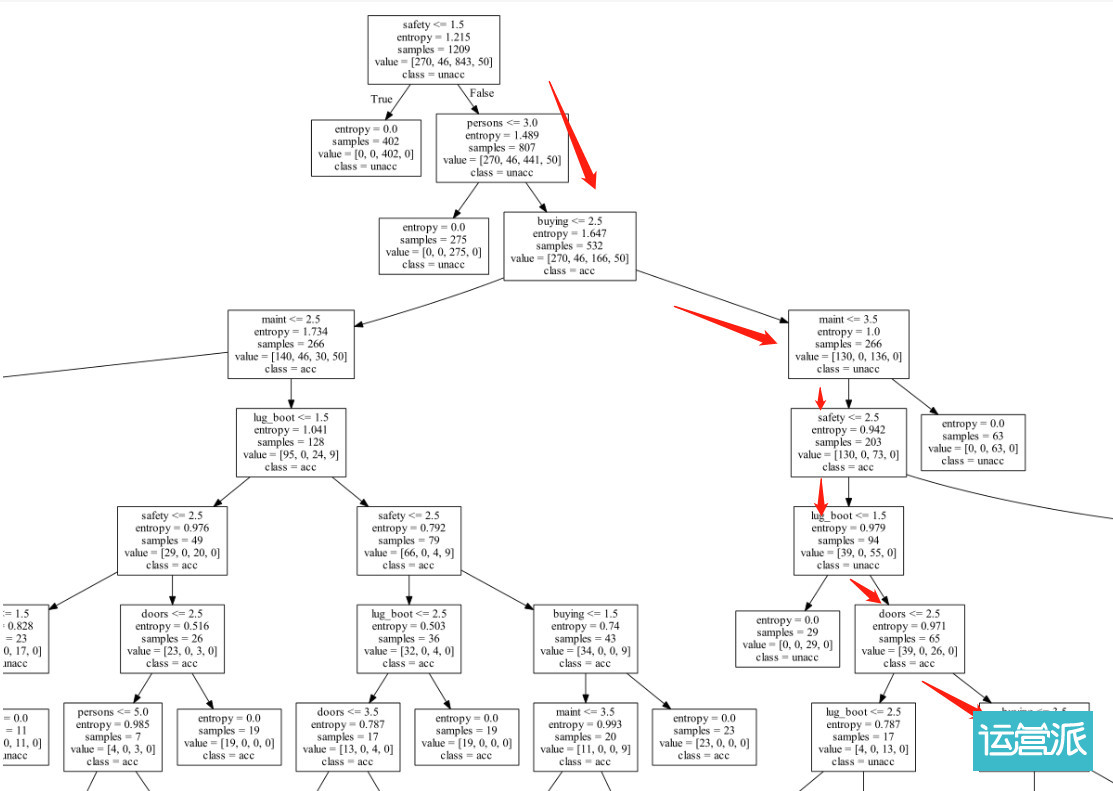
决策树算法是如何计算的?
假定我们需要了解的是用户如何能够付费,那付费与否就是要考察的因变量,也是需要决策树根据变量情况预测的值
我们把整个数据集按照20%,80%分成训练集和验证集,即为一部分拿来训练模型,让模型从数据里找出特征因素,一部分用来印证和预测,判断模型和挑选的特征变量是不是有效的,拟合度如何
从自变量里抽取2个既定值,与因变量进行卡方检验;如卡方检验显示2者关系不显著,正面2个既定值可以合并。不断减少自变量的取值数量,知道该自变量所有取值均呈现显著性。
例如,我们的数据里有130个自变量,其中很多我们都不知道是否和用户是否付费相关,不知道用户每周活跃次数和用户付费是否相关,不知道用户尝试了某个功能是否和用户付费相关,这时就通过决策树的卡方检验通过距离来判断自变量和因变量之间是否相关
通过比较找出最显著的自变量,并按照自变量的最终取值对样本进行分割,也就是形成多个不同的树(一般CHAID生成两个树节点)
最终展示出所有和用户付费与否相关的决策点,其中可能是,直播功能创建超过3个,付费的概率高达80%,决策树就帮助我们剔除了不相关或关联性不显著的自变量,告诉了我们,到底什么才会导致用户的转化付费。
本文由 @LunaDeng 授权发布于运营派。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
 等我一分钟 我去找个夸你的句子
等我一分钟 我去找个夸你的句子
 这世上美好的东西不多,牛起来要人命的你就是其一!
这世上美好的东西不多,牛起来要人命的你就是其一!
 不要厉害的这么随意,不然我会觉得我又行了
不要厉害的这么随意,不然我会觉得我又行了
 这就很离谱了,老天爷追着喂饭的主儿~
这就很离谱了,老天爷追着喂饭的主儿~
 我要是有这才华,我走路都得横着走!
我要是有这才华,我走路都得横着走!
 对你的作品崇拜!
对你的作品崇拜!
 反手就是一个推荐,能量满满!
反手就是一个推荐,能量满满!
 感谢分享
感谢分享































