
从技术视角看,如何更多、更好、更快地实施 A/B 试验
A/B 测试被更多人熟知的是持续观察并对照按一定规则分成的A、B两组测试样本,基于数据反馈辅助优化决策,其背后复杂的数学理论和试验基础设施却往往被人忽视。作者就本文重点探讨了 A/B 测试在提升功能、性能这两个维度的技术实践,一起来看看吧。

A/B 测试被更多人熟知的是持续观察并对照按一定规则分成的A、B两组测试样本,基于数据反馈辅助优化决策,其背后复杂的数学理论和试验基础设施却往往被人忽视。
目前,国内一线互联网公司大多采用自研的方式建设 A/B 测试平台,而中小互联网企业和传统行业的企业则会选择自采的方式建设 A/B 测试平台。
在面对标准不一的多种 A/B 测试平台时,企业该如何选择?
参照 Google 重叠试验框架——更多、更好、更快地试验,并结合我司 A/B 测试服务数十家客户的实践,我们从不同维度总结出评价 A/B 测试平台的标准:
- 功能:支持丰富的试验人群定向和指标管理配置,同时进行多个试验的可扩展性、灵活性
- 性能: A/B 测试的性能越高,对实际业务造成的延迟越小,对 C 端客户的体验越好
- 稳定:A/B 测试平台要保证足够高的 SLA,A/B 故障不应该影响正常业务运行
- 效率:降低试验的实施和分析成本,通过标准化的试验指标计算快速发现、终止不符合预期的试验
- 易用:降低试验的实施门槛,帮助没有 A/B 测试基础的小白快速上手、避免踩坑
基于上述评价标准,接下来我们将重点探讨 A/B 测试在提升功能、性能这两个维度的技术实践。
一、功能:基于数据体系与模型算法的成功演绎
A/B 测试平台功能维度的建设核心主要表现在两方面:试验人群定向和指标的支持依赖于底层的数据体系建设;同时进行多个试验的可扩展性和灵活性取决于试验模型和分流算法的设计方案。
1. 数据体系
Event-User-Item(用户-事件-实体)数据模型能够对用户行为数据标准化抽象,从而支持丰富的用户行为指标建设,为企业提供强大、便捷的分析能力。
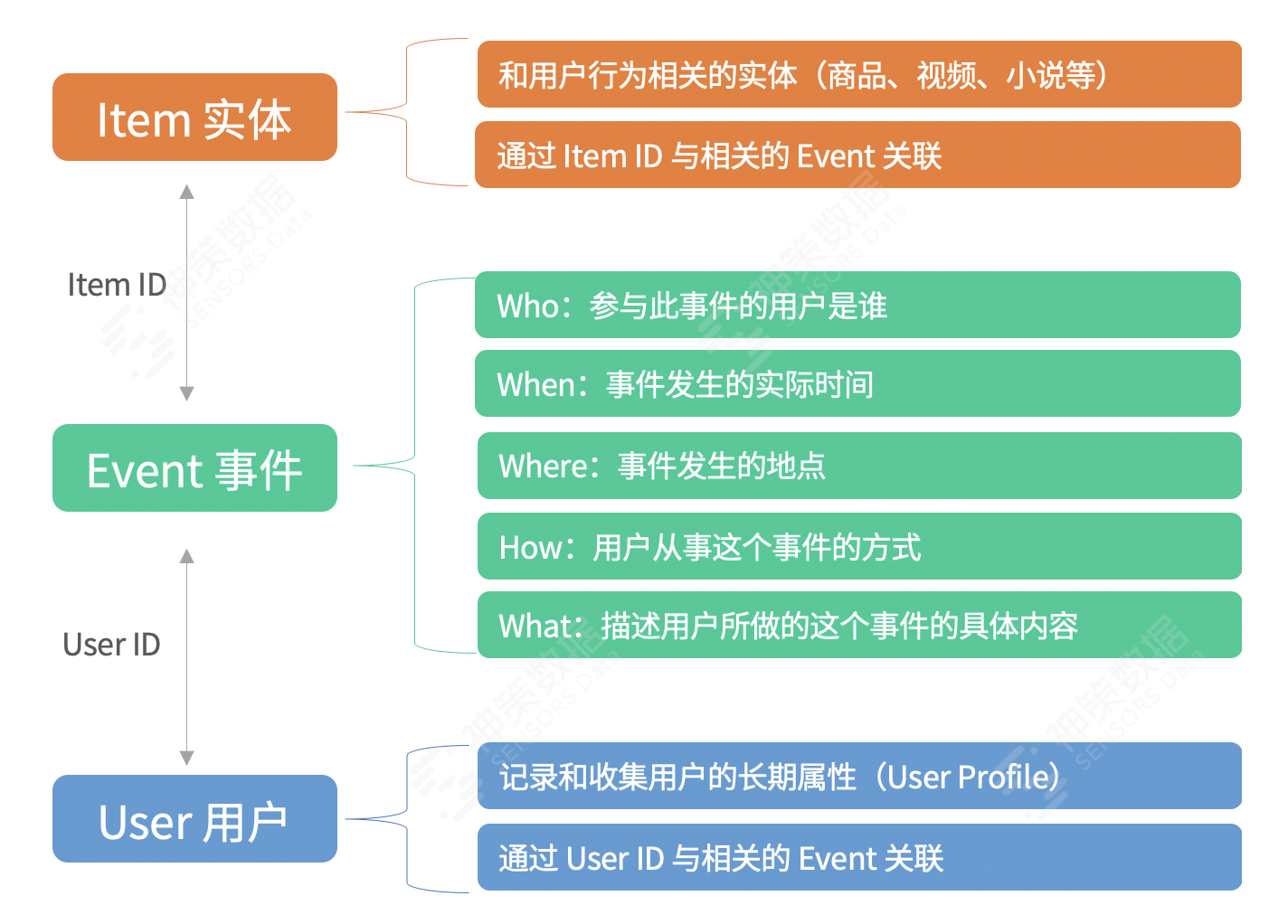
Event-User-Item(用户-事件-实体)数据模型
A/B 测试构建于数据体系之上,基于数据根基平台和用户画像体系,支持的全部画像标签和分析指标可以更便捷地应用到 A/B 测试中;与此同时,A/B 测试产生的结果又会遵循标准数据模型回流到数据平台中,如下图所示:
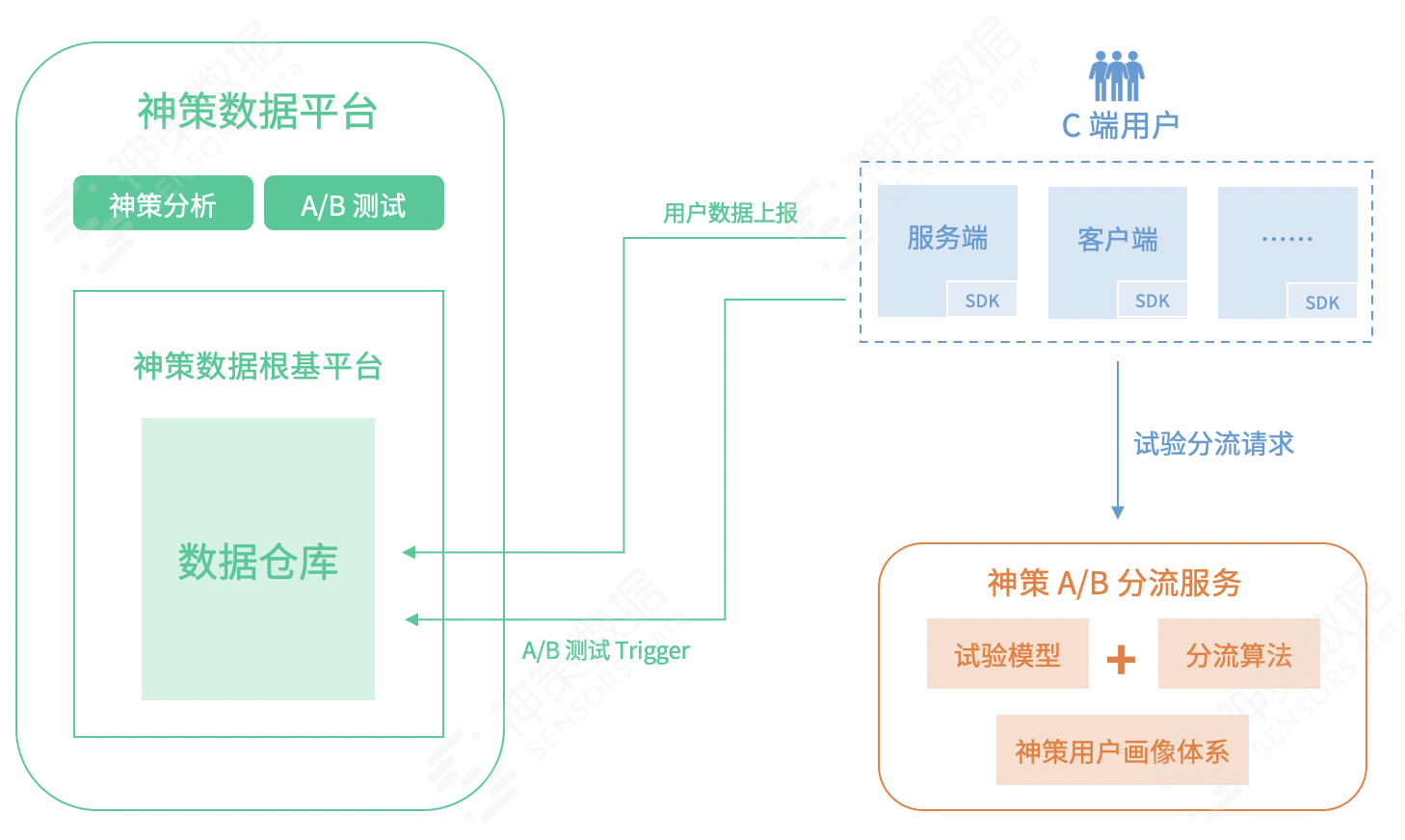
采用上述架构,能够为 A/B 测试带来强大的试验人群定向和指标分析能力,所具备的独特优势如下:
- 支持公有 SaaS 化部署和私有 PaaS 化部署两种方案,满足多种场景的差异化需求,而用户核心数据则私有存储在客户环境中,保障数据安全;
- 既可以作为独立产品支持客户 A/B 测试的需求,也可以结合数据分析产品为客户实现数据分析感知、目标决策、线上测试验证、试验数据反馈打通的 SDAF 闭环;
- A/B 测试的数据回流到平台后,既能够丰富用户行为分析指标种类,又能够提供用户人群圈定功能,进一步增强试验分析能力,不断形成正向反馈。
2. 模型算法
要具备同时进行多个试验的可扩展性和灵活性,本质是要解决在有限的流量(比如仅能满足 2 个试验的样本量)前提下同时进行多个试验无法保证隔离的矛盾。
具体来说就是:流量在试验之间互斥可以保证隔离性,但多个试验同时运行所需要的流量规模最好同时满足;让流量同时经过多个试验,即正交,需要解决试验效果出现互相干扰的问题。
而试验互斥和正交的背后则隐藏了一系列复杂的技术和业务问题。
(1)试验互斥
怎么保障试验有公平获取到流量的机会?比如存量试验消耗了全部流量导致新上线的试验无法分配到流量而出现“流量饥饿”。
怎么保障试验流量的分配使用是随机且公平的?比如某个试验消耗了全部男性用户的流量,导致其他互斥的试验流量全是女性用户。
对于一个新增流量规模为 X(X<100%)的试验,如何保证该试验得到精确定义的流量规模?
(2)试验正交
同时经过两个试验之间的流量如何保证均匀打散,实现流量正交,从而保证试验之间的影响是一致的,对试验效果评估不会出现相互干扰。
天然存在相互干扰的试验如何解决?比如同一个按钮,试验1设置背景为红色,试验2设置文字为红色,同时命中这两个试验的用户将会看到一个没有文字全是红色的按钮。
除此之外,我们还需要保证每个试验配置的灵活性,比如差异化的人群定向和试验流量规模等。
解决上述问题的根本方法是构建一套逻辑严谨且扩展灵活的试验模型,加上能够实现严格正交的算法。
以前人为鉴,筑后世基石,参照Google重叠试验框架,结合业界优秀的 A/B 测试平台建设经验,我们推演出如下试验模型:
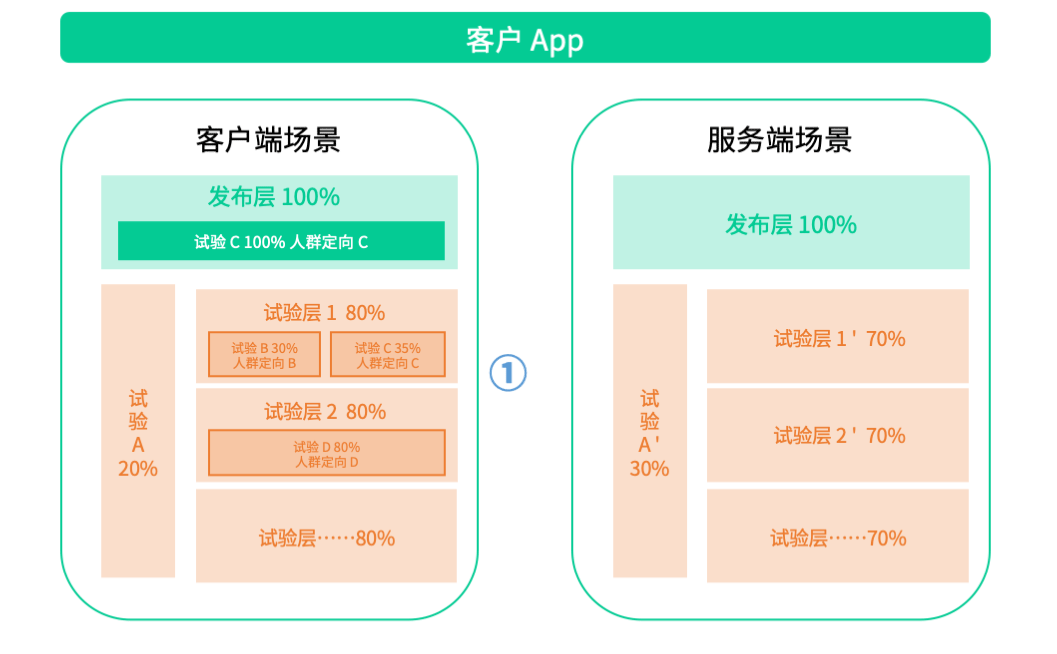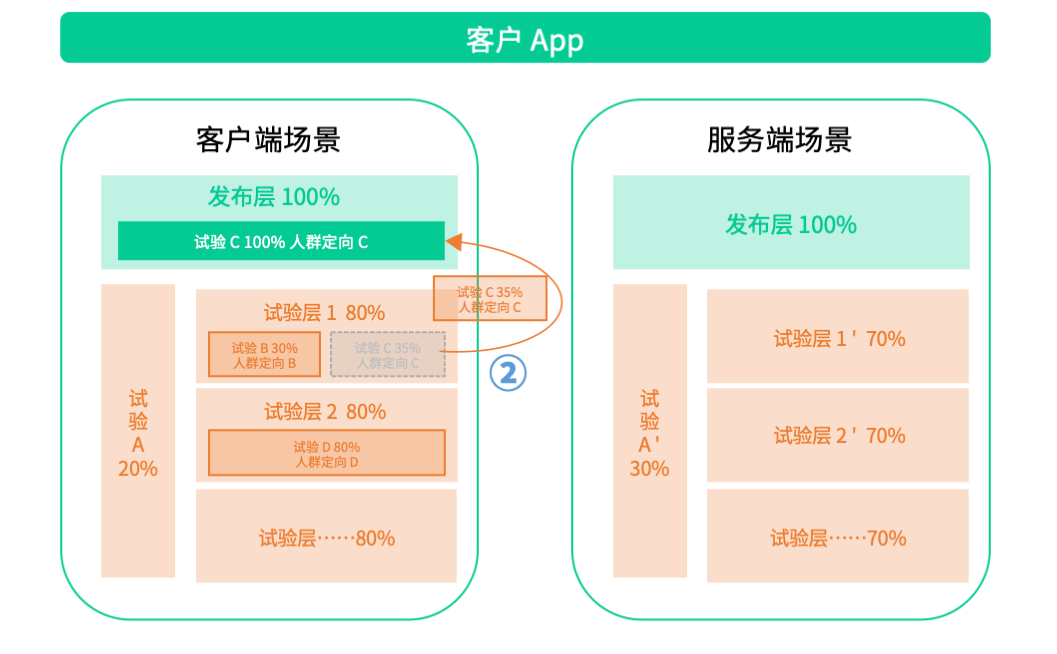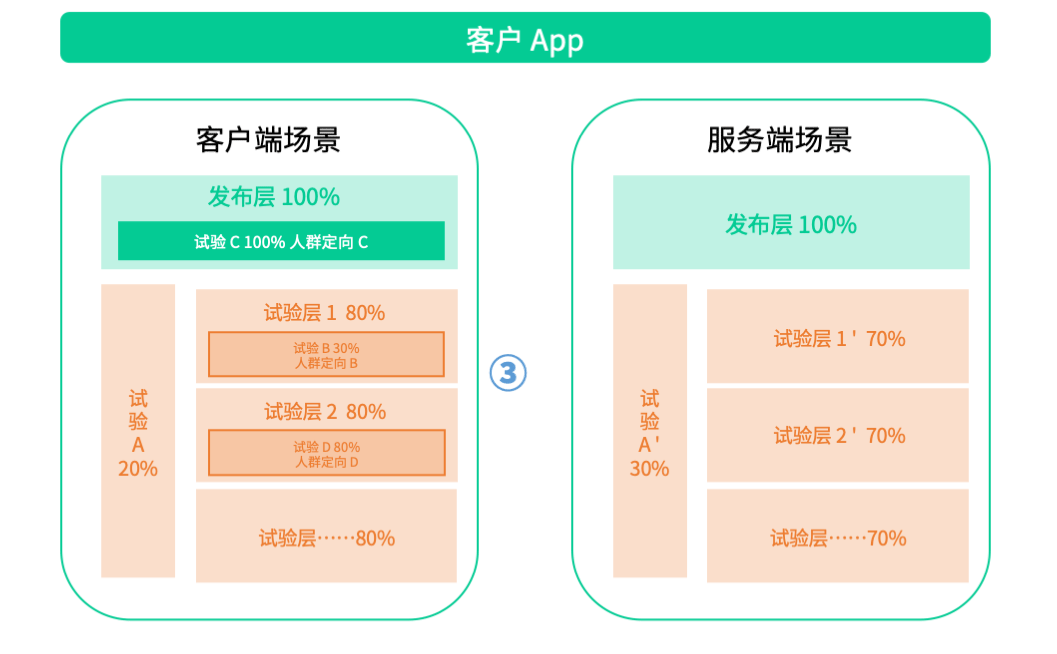
- 在试验域、试验层和试验的模型上,我们支持精确的流量定义、严格的流量分配归属和差异化的人群定向功能;
- 既支持独占域的试验场景规划,又支持对效果显著的试验进行全量发布;
- 同时我们还保留了对如下复杂重叠试验模型的扩展支持,也将会面向部分存在循环嵌套重叠试验需求的客户开放该功能。
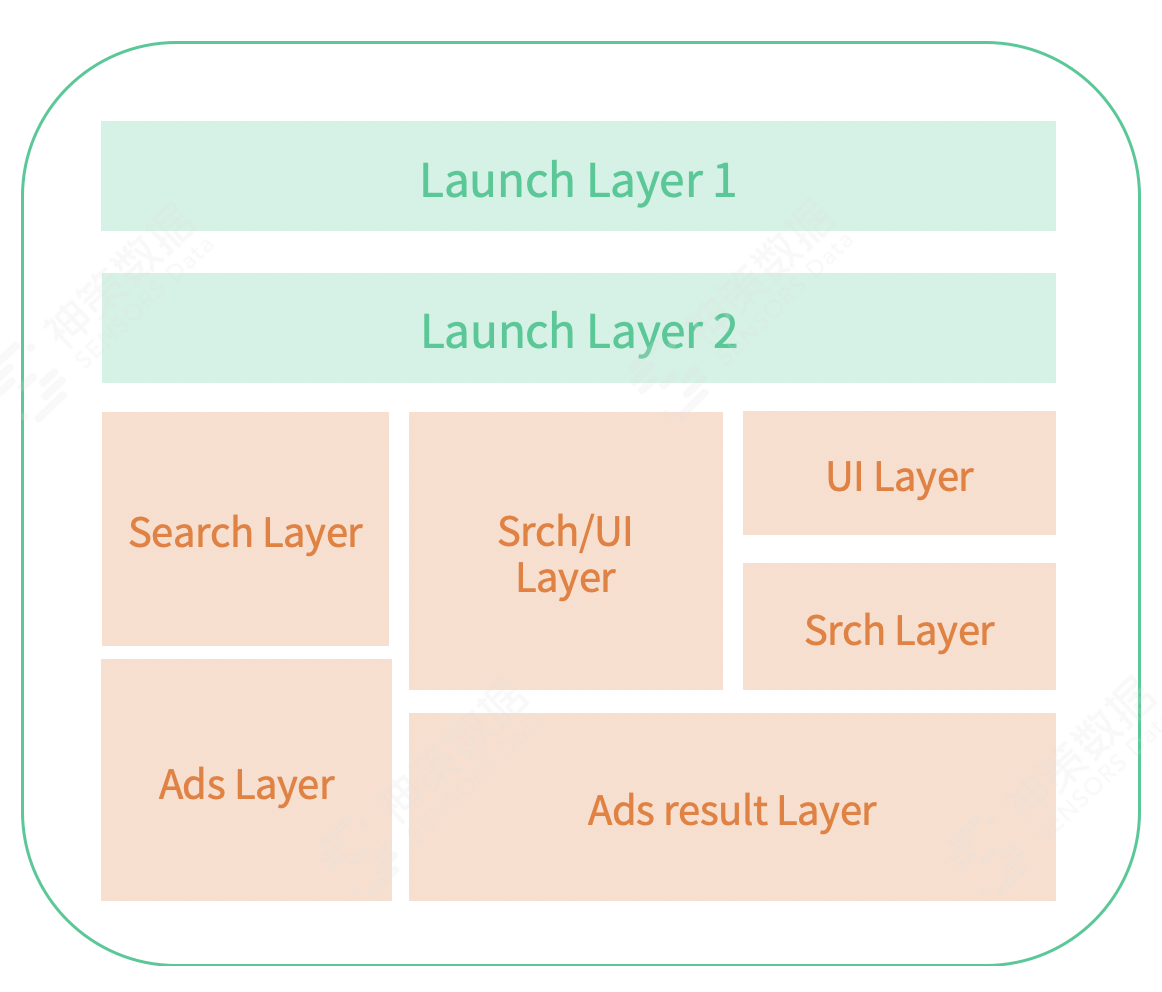
基于上述试验模型设计,我们可以充分保证同时进行多个试验的可扩展性和灵活性,但仍有可能面临一个很关键的问题——在多个试验层重叠的场景下,如何保证试验之间的流量是均匀打散,严格正交的?
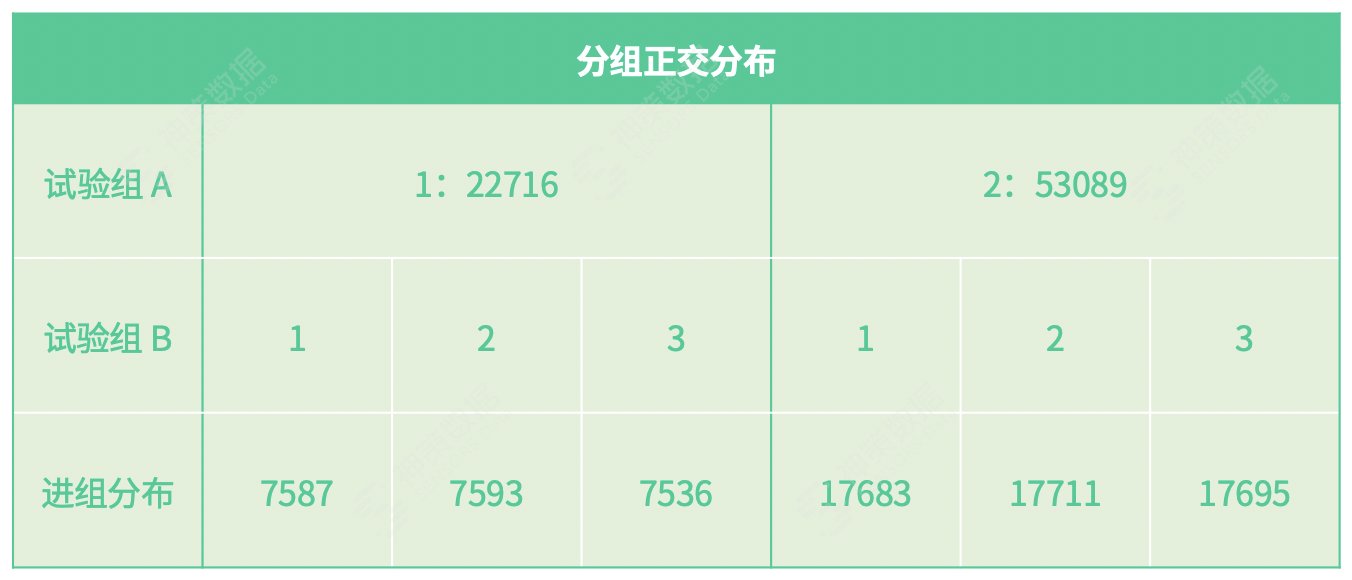
这里我们对 hash 因子和 hash 算法进行了大量的调研和验证,最终得到了严格正交的流量分配结果,如下:
二、性能:基于链路拆分与治理降低 A/B 测试耗时
大多数客户在使用 A/B 测试平台之前都存在疑虑:A/B 测试的性能如何,会不会对 C 端客户的响应增加延迟?
答这个问题的关键是要先搞清楚一次 A/B 测试的过程:
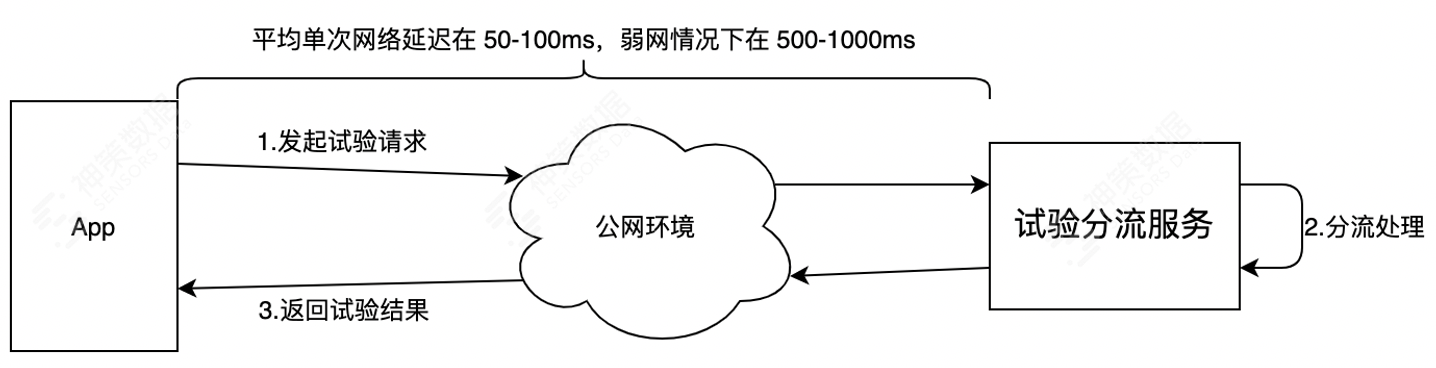
如上图所示,1 次 A/B 测试请求的耗时主要包含 2 次公网传输耗时和 1 次分流服务处理耗时,而公网传输耗时是 App 使用过程中不可避免会存在的。
所以降低 A/B 测试延迟的根本在于降低分流服务的处理耗时和规避试验请求的公网传输耗时。
针对试验分流服务,我们进行了多方面的探索和尝试。
- 增加试验结果分布式缓存和持久化存储,降低存储查询/写入次数,提升存储读写效率;
- 前置过滤试验人群定向条件,提升试验分流效率;
- 整体服务和存储支持快速水平横向扩容,保证服务响应耗时保持在平稳状态;
- 优化试验模型和抽象,简化分流业务流程;
- 拆分强弱依赖处理逻辑,部分弱依赖操作异步化。
基于上述实践,最终实现了整体分流服务单次平均处理耗时在 11-12ms。
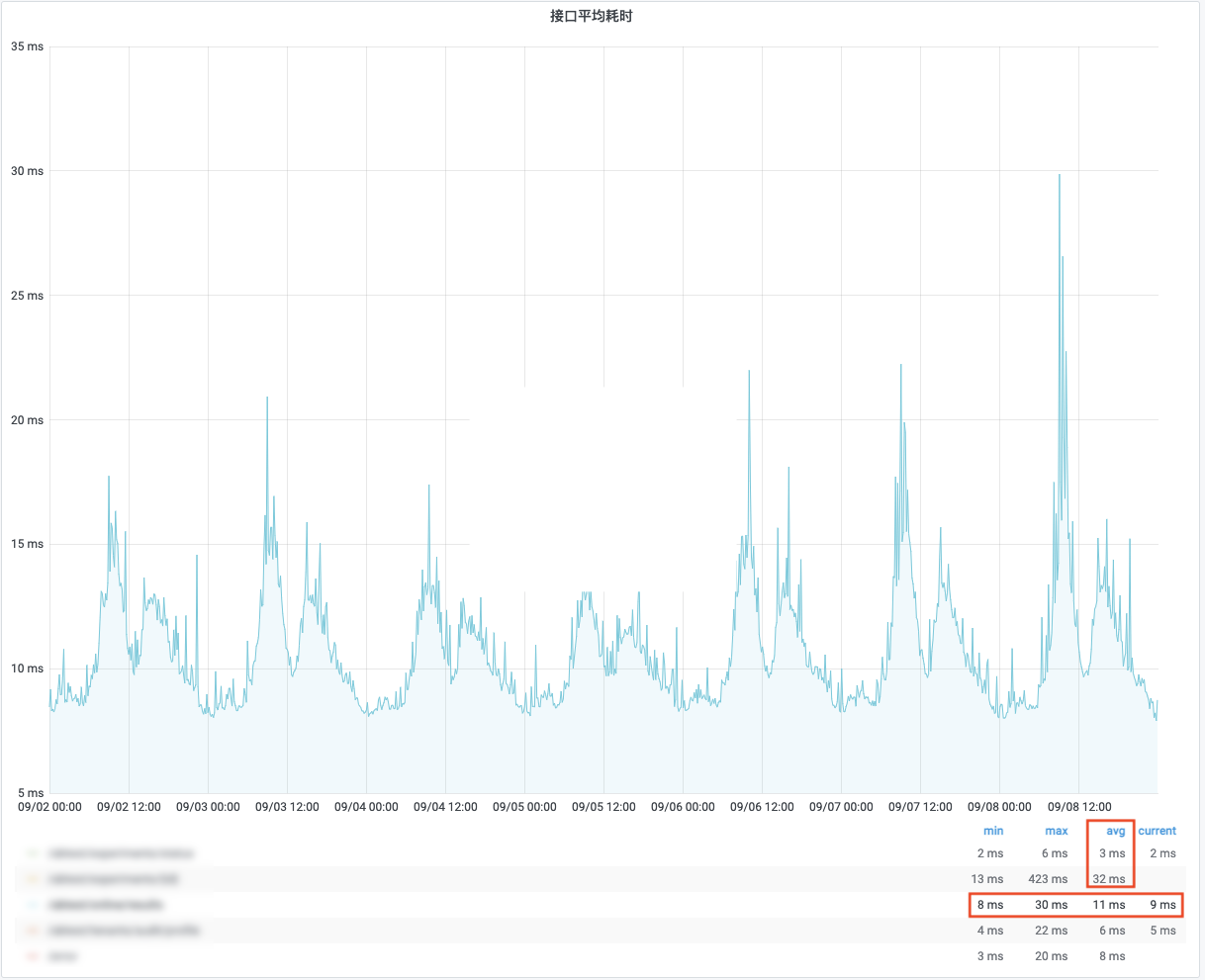
接下来,通过对服务的重构拆分,A/B 测试试验分流的单次平均处理耗时会降低到 8ms 以内,TP90<10ms。
那么,对于占比超过 80% 的公网请求耗时该如何规避呢?我们可以简单拆分为通过缓存+异步请求的通用场景和必须首次请求的特殊场景。
1. 通用场景
在大多数场景中,C端用户的试验分流结果是可以被预先获取并存储的。
针对这类通用场景,我们在多个端的SDK集成了异步定时发起试验请求+本地缓存的方案,如下图所示:
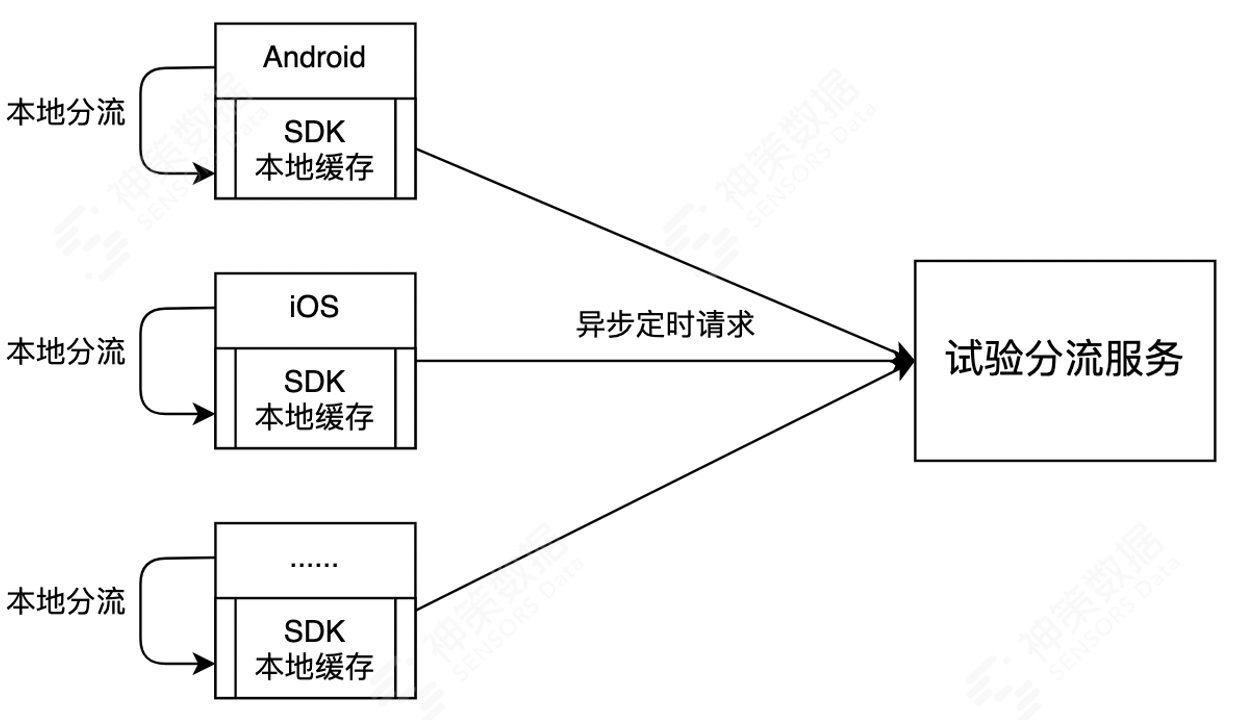
通过本地缓存,在对 C 端客户分流时我们就可以绕过一次实时的远程试验请求,直接在本地进行试验分流。
2. 特殊场景
在部分特殊场景中,试验分流结果只能在首次加载时获取,无法预先被加载,例如投放落地页场景中用户从流量平台跳转到B端平台App,因为用户信息无法提前获取到,导致在落地页加载之前必须实时发起一次试验请求。
针对这部分特殊场景,可以考虑通过前文提到的私有化部署方案来规避。
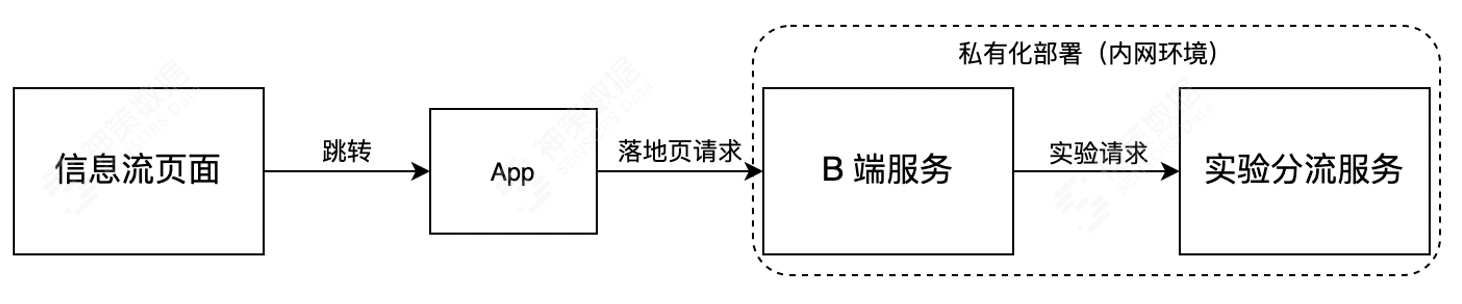
通过私有化部署方案,将公网的试验分流请求转化为内网请求(平均网络延时低于 20ms),就规避了试验请求过程中不稳定的公网传输耗时。
接下来,我们也将持续输出功能和易用性相关实践,例如智能化的试验配置、分层、试验问题检测和试验控制,帮助渴望踏入A/B测试大门的客户直接上手,自动规避试验陷阱,即便是不懂复杂理论的用户,也能轻松完成 A/B 测试。
请期待更多关于 A/B 测试在稳定和效率维度的技术实践分享!
作者:【温先辉】
来源:微信公众号“神策数据(ID:SensorsDataCrop)”
本文由 @【神策数据】原创发布于运营派。未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。
 等我一分钟 我去找个夸你的句子
等我一分钟 我去找个夸你的句子
 这世上美好的东西不多,牛起来要人命的你就是其一!
这世上美好的东西不多,牛起来要人命的你就是其一!
 不要厉害的这么随意,不然我会觉得我又行了
不要厉害的这么随意,不然我会觉得我又行了
 这就很离谱了,老天爷追着喂饭的主儿~
这就很离谱了,老天爷追着喂饭的主儿~
 我要是有这才华,我走路都得横着走!
我要是有这才华,我走路都得横着走!
 对你的作品崇拜!
对你的作品崇拜!
 反手就是一个推荐,能量满满!
反手就是一个推荐,能量满满!
 感谢分享
感谢分享
































献上津津的膝盖,日常膜拜大神
感觉运营就是个苦逼活
逻辑思维能力 分析能力 真的需要提升的太多了!!
精彩的文章,甚是精彩
作者文章写的很好,学习了。